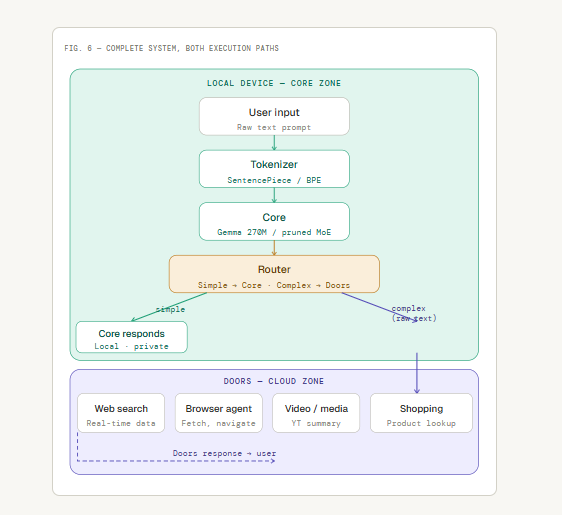
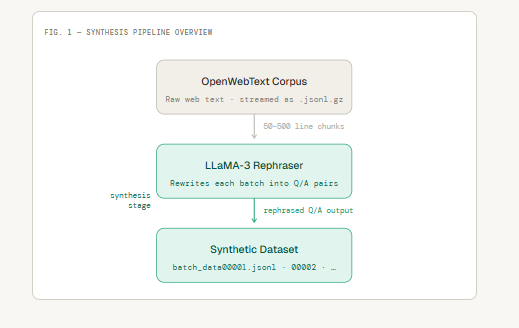
Description on the architecture of godel ai
synthetic corpora using local llm
founder@atomtechnologies.org